📦 Products Dashboard
Active product development and architecture
Last updated: Feb 8, 2026 4:15 PM HST
Progress Update: Feb 8, 2026
For: Joana & Victor Meeting (Feb 9, 2026)
Summary of what was accomplished today and the strategic direction emerging from the Charlie partnership meeting.
Supabase Migration Complete
All 10 dashboards now use Supabase for persistent data. No more localStorage. Data survives browser clears.
Akira PMO Multi-Agent Deployed
3 agents running: Coordinator, Estimator, Executor. Each owns their outcomes. Built on ownership/empowerment model.
Akira ↔ Jarvis Protocol
GitHub-based handoff format created. Templates for issues, completion reports. Sparse → fully-specified workflow.
Context Persistence Middleware
SQLite-based plugin integrated into OpenClaw. Sessions now survive compaction. No more 4-hour tasks for 10-min work.
🐝 Two AI Swarms Architecture
From the Charlie Partnership Strategy Meeting (Feb 8)
AKIRA
Tony's Swarm
Business & PM Layer
- Profiling (customer → priorities)
- Prioritization (effort vs value)
- Scope specification
- Verification & acceptance
GitHub
Source of Truth
JARVIS
Charlie's Swarm
Technical Execution Layer
- Autonomous coding pipeline
- Implementation from specs
- Testing & deployment
- Completion reporting
The Flow: Sparse → Specified → Shipped
🔓 The Unlock: Charlie's insight — "Linear tickets are like a title and one sentence. That's not enough. You need to inflate them into actual work." Akira's job is to take sparse input and produce fully-specified, implementation-ready tickets for Jarvis.
🚧 Key Blocker (Before Alpha)
Dedicated Machines Required
Need separate infrastructure for clean IP separation from Kindo. Cannot use Kindo resources for Akira/Jarvis work.
Status: Must resolve before Basis alpha engagement.
Options: Personal machines, cloud instances, or Tony's existing hardware.
💰 Revenue Context
Current: Kindo
Six-figure consulting work (ongoing)
Alpha: Basis
First external customer (Sean partnership)
Potential: 8-Figure
Larger opportunity identified in meeting
📋 For Joana: Akira Status
Files Downloaded & Analyzed:
• portfolio-manager-with-context.zip ✅
• portfolio-manager-standalone.zip ✅
• reklaim-estimator-vercel.zip ✅
• reklaim-estimator-lovable.zip ✅
What Greg Built from Joana's Source:
• 3 OpenClaw agents (Coordinator, Estimator, Executor)
• Ownership/empowerment model integrated
• Multi-agent handoff protocol
Key Insight Preserved: Story Points × 2 = raw hours → × 1.7 drag factor. 33/33/34 Promise/Stretch/Buffer model.
🔧 For Victor: Technical Stack
| Component | Location | Status |
|---|---|---|
| Akira Agents | ~/.openclaw/agents/akira-*/ |
✅ Running |
| Context Plugin | ~/.openclaw/extensions/context-persistence/ |
✅ Integrated |
| Handoff Protocol | workspace/akira-jarvis-protocol/ |
✅ Complete |
| Dashboard DB | Supabase: mmwbiogqmgmtxboipyko |
✅ Migrated |
| Dashboard UI | greg-dashboard.vercel.app | ✅ Deployed |
⏭️ Next Steps
Resolve dedicated machines blocker — Required before Basis alpha
Test Akira agents with real task — Validate ownership model in practice
Formalize business entity — Tony's Hawaii LLC for IP/revenue split
Profiler Engine design — The missing piece (customer calls → priorities)
Exec.AI — Executive Prioritizer
Personal productivity prioritizer powered by AI. The "High Performer Hypnagogic Workflow" — capture clarity during peak creative states (3am–6am), digitize via WhatsApp/photos, categorize in Stream dashboard, review with AI, route to execution. Today's session was the first live prototype.
📋 Core Concept
Executive Prioritizer works off the same engine as current estimator. Estimates level of effort vs value, then prioritizes based on that.
Leverages data from Greg's tracking of how long it takes user to develop idea, deploy it, and begin earning revenue.
Feature: Visualize user's AI chats into visual dashboards. Dashboard tracks AI chats and progress of discussions on a timeline.
🚀 Live Prototype: Feb 6, 2026 Session
Today's session WAS the Exec.AI workflow in action. Here's what we did:
The High Performer Hypnagogic Workflow:
| Phase | Time | What Happened |
|---|---|---|
| 1. Capture | 3am–6am | Tony in hypnagogic state, wrote ~40 index cards of clarity/ideas |
| 2. Digitize | 7:00am | Photos of cards sent via WhatsApp → Greg captured 41 items to Stream |
| 3. Categorize | 7:20am | Bulk categorize in Stream dashboard: Exec.AI, Technical Setup, Akira PMO, Partnerships, etc. |
| 4. Review & Explain | 7:30–9:00am | Greg answered architecture questions, explained how systems work, provided context |
| 5. Route & Execute | 9:00–10:30am | Moved items to To-Do, Products dashboard. Built dashboards. Sent emails. Downloaded Akira source. |
Session Results:
• 41 items captured → 7 remaining in Stream (17 routed, 17 done/purged)
• 11 items in To-Do list
• 3 emails sent (Joana, Victor, Alex)
• 4 new dashboards built (Stream, Standup, Products, To-Do refresh)
• Akira PMO fully analyzed (4 zip files downloaded, architecture documented)
• Products dashboard created with Exec.AI + Akira sections
Key Insight: The "AI sells fastest when it doesn't require humans to change" principle in action — Tony's existing workflow (handwritten cards, WhatsApp photos) stayed the same. Greg adapts to capture and process.
✅ Tasks
Build time tracking mechanism for idea lifecycle (start → deploy → revenue)
Build dashboard/tracker for ongoing discussions
Prototype using Multicity Living Chat export from Grok
Akira PMO — AI-Driven Project Management
Rebuilding Joana's Estimator and Portfolio Manager inside OpenClaw. Goal: replicate and enhance the AI PMO agent capabilities without external dependencies on Lovable/Vercel infrastructure.
🏗️ Architecture Analysis
| Component | Original | OpenClaw Rebuild |
|---|---|---|
| Estimator AI | Gemini 2.5 Flash via Lovable Gateway |
Direct Anthropic/Gemini API calls |
| Portfolio Manager AI | Claude Sonnet (two-pass analysis) |
Same - Anthropic API |
| Backend | Supabase Edge Functions | Local scripts or OpenClaw skills |
| Database | Supabase (tickets, epics) | Local JSON or SQLite |
| Frontend | React + Vite + Tailwind | Canvas dashboards or Vercel |
| "RAG" Context | Hardcoded prompt injection | SKILL.md / workspace files |
💡 Key Insights
No actual RAG/embeddings needed. The "RAG" is hardcoded context strings (KINDO_SECTIONS_SUMMARY, CYCLE_PLANNING_RULES) injected into prompts. OpenClaw can do this natively with skills and workspace files.
Estimator core logic: Story Points × 2 = raw hours → × 1.7 drag factor = drag hours. 33/33/34 rule: Promise (first 33%), Stretch (next 33%), Buffer (34%).
Portfolio Manager: Pure calculation engine for capacity (engineers × 250 days × 6 hrs ÷ drag), payroll coverage, and milestone-based cash flow.
🔓 The Unlock: PROFILER → PRIORITIZER → EXECUTOR → VERIFIER
• Jarvis (Charlie) executes perfectly but doesn't decide what matters
• Akira prioritizes but needs human-supplied priorities
• The Gap: Automating the Profiler function (turning customer calls → structured priorities)
• Charlie currently IS the profiler — scales linearly with calls he can attend
Akira = Profiler + Prioritizer. Jarvis = Executor. Together = The Unlock.
📂 Source Files Downloaded
portfolio-manager-with-context.zip (477.7 KB)
portfolio-manager-standalone.zip (289.7 KB)
reklaim-estimator-vercel.zip (305.6 KB)
reklaim-estimator-lovable.zip (305.6 KB)
🔜 Next Steps
Extract Estimator system prompt and create OpenClaw skill
Build Portfolio Manager calculation engine as local script
Create dashboard for visualizing backlog and capacity
Waiting on Joana's email response for additional context
📁 How to Modify SOUL.md, USER.md, AGENTS.md
Location: /Users/greg/.openclaw/workspace/
• SOUL.md — Who Greg is (personality, style, boundaries)
• USER.md — Who you are (name, preferences, context)
• AGENTS.md — How Greg behaves (memory protocol, heartbeats, safety)
• TOOLS.md — Local notes (contacts, device names)
How to modify: Direct edit in any text editor — changes take effect next turn. Or ask Greg: "Update SOUL.md to be more concise"
📋 JSON Files & File-Based Memory
Location: /Users/greg/.openclaw/workspace/memory/
• YYYY-MM-DD.md — Daily logs (what happened each day)
• MEMORY.md — Curated long-term insights
How Greg uses them: Every session loads today + yesterday's logs. Main sessions also load MEMORY.md. memory_search does semantic search across all memory files.
You can: Read/edit directly, ask Greg to update — they persist across sessions/restarts.
📂 Drive Folder Access — How to Use It
Best uses for your workflow:
• Akira documentation — Estimator/Portfolio Manager specs
• Chat exports — ChatGPT/Claude as text files
• Research papers — Gartner PDFs for summarization
• Reference docs — Anything for Greg's context
How: Use gog skill to search/read Drive files, or tell Greg "read the doc at [link]"
Recommendation: Create a Greg-Context folder in Drive for docs you want Greg to reference.
Current: Joana shared folder at Akira PMO: Rebuilding Estimator & Portfolio Manager
🤖 Sub-Agents vs Multiple OpenClaw Instances
| Approach | Pros | Cons |
|---|---|---|
| Sub-agents (within Greg) | Shared memory, Greg orchestrates, simpler | Less isolation |
| Multiple instances (Greg + Akira) | Full isolation, separate identities | More setup, no shared context |
Recommendation for Akira:
• Short-term: Use sub-agents within Greg for Estimator/Portfolio Manager tasks
• Long-term: If Akira becomes a product for others, spin out to its own instance
📅 Reminder set: Revisit sub-agents decision in 24 hours (Feb 7, 2026 ~9:22 AM)
⚖️ Value Prioritization — The Pareto Engine
🎯 Core Principle: The 80/20 rule — 80% of human-perceived value comes from 20% of the features. This depends on judgment: skillfully assessing the situation and human preference.
📊 WHAT'S PRESENT IN AKIRA
| Component | What It Does | Limitation |
|---|---|---|
| Stack Ranking | High priority features (from PM/customer) ordered by importance | Assumes priorities already known |
| Effort Estimation | Story Points × 2 × 1.7 drag factor = hours | Estimates effort, not value |
| Priority × Effort Matrix | Cross-reference: High Priority + Low Effort → Ranked Higher | Requires human-supplied priorities |
| Promise/Stretch Model | Creates commitment clarity (guaranteed vs aspirational) | About commitment, not discovery |
| Hexagon of Success | 6 criteria for trade-off decisions | Balances competing concerns, doesn't rank features |
💡 The Explicit Value Algorithm:
1. Human identifies HIGH PRIORITY features
2. Estimator calculates LEVEL OF EFFORT
3. Cross-reference: High Priority ∩ Low Effort = HIGHEST VALUE
4. Result: Deliver more perceived value in less time
This is also the core engine for Exec.AI Executive Prioritizer.
❌ WHAT'S MISSING — THE GAP
Preference Elicitation
How does AI learn what the human actually values?
Value-Scoring Model
How do you quantify "human-perceived value"?
Prioritization Algorithm
Given N features, how do you identify the vital 20%?
Feedback Loops
Does the system learn "we thought X was high-value but client cared more about Y"?
🔮 THE MISSING PIECE: To-Do Item #10 — "Explain Profiler & Multi-Agent Distribution Product Customizer"
This is where Tony will explain the Human Profiler Engine — the mechanism for assessing perceived value based on understanding the human. This completes the Pareto judgment loop.
Status: Waiting for Tony's explanation session
📝 Summary: The Estimator is really an effort estimator, not a value estimator. It assumes priority input from humans. The Profiler fills the gap by modeling human preference — turning "what does this person actually care about?" into actionable priority weights.
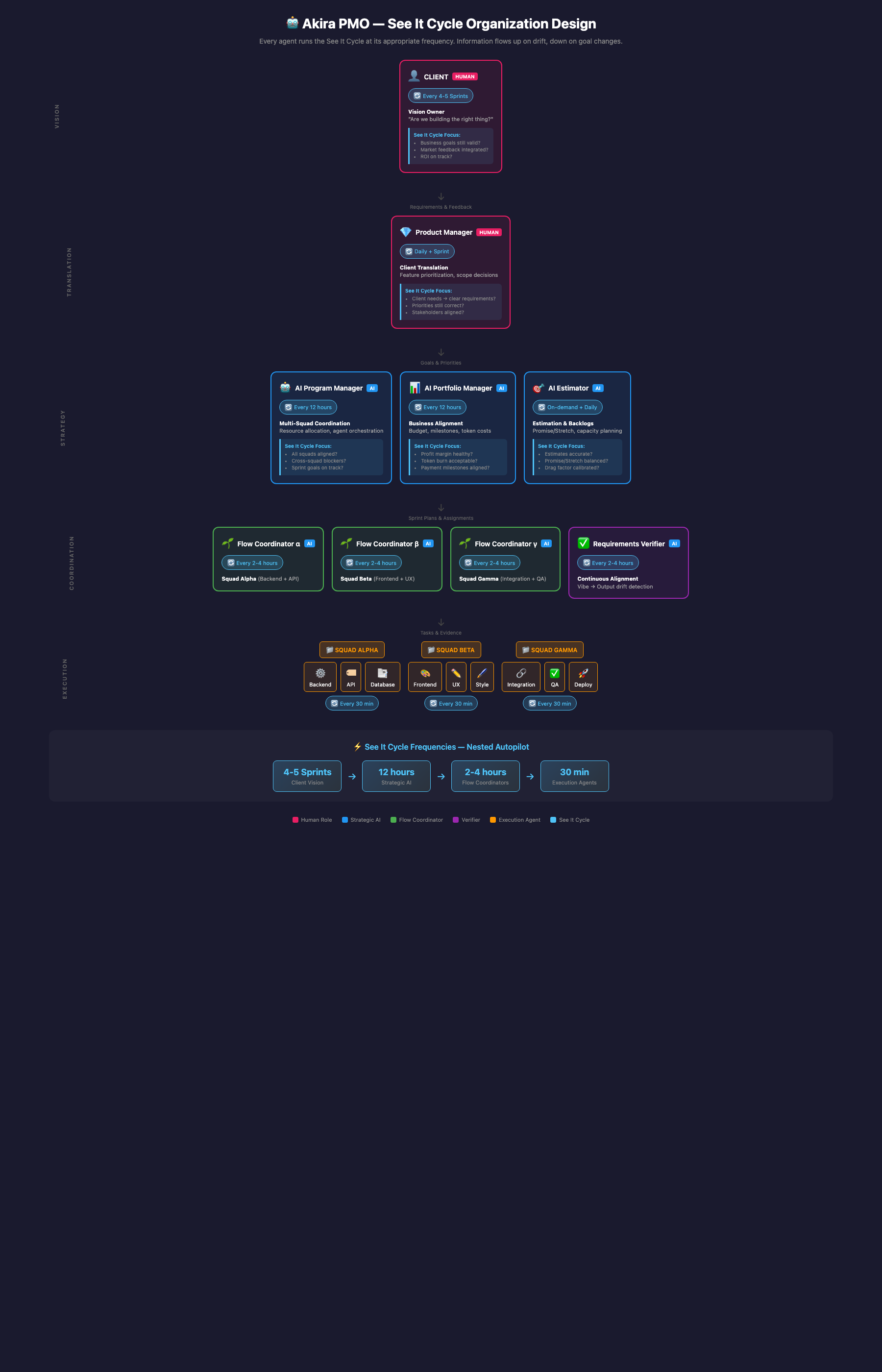
🚀 Why Auto Pilot Projects (APP) Works for Multi-Agent Orchestration
👁️ SHOW ME DON'T TELL ME
PERFECT for AI. Agents hallucinate completion — evidence-based verification catches this.
⏱️ HOUR-BASED CYCLES
AI works 24/7. 12-hour "sprints" = 100x faster iteration than 2-week human sprints.
🎯 PROMISE VS STRETCH
Forces unambiguous scope. Promise = guaranteed, Stretch = aspirational. No hallucinated scope.
🏗️ HIERARCHICAL COORDINATION
Program Manager → Flow Coordinators → Squads. Mirrors supervisor/worker patterns.
✅ REQUIREMENTS VERIFIER
"Vibe prototype vs squad output" = automated diff/testing. Continuous alignment.
🚨 AGENT 215 PROTOCOL
Idle detection is critical. No commits for 2+ standups → diagnostic intervention.
⚠️ ADAPTATIONS NEEDED
No Ego
Agents don't self-correct from peer pressure → explicit failure handling + retry logic
Structured I/O
Agents need structure → JSON-formatted status reports
Auto Verification
Agents can't eyeball → automated tests, visual diff, deploy checks
No Reflection
Agents don't learn from retros → prompt refinement, context memory
Infinite Loops
Agents can loop forever → tighter timeouts, cost guardrails
Token Burn
API burn is real → Portfolio Manager needs hard limits
⚡ THE KILLER FEATURE: See It Cycle at Machine Speed
Humans can't run this loop every 30 minutes. AI agents can. That's the leverage.
💡 Bottom Line: APP is built on verification, not trust. That's why it works better for AI agents than humans. It's one of the few human methodologies that translates because it doesn't rely on ego, peer pressure, or human judgment.
10X Coder — Sub-Agent Protocol
First sub-agent in the Chief of Staff team. Uses Two-Phase Spawn Protocol with Contract system. The workout-images-001 cycle was the first real test — results mixed but learnings valuable.
📊 Cycle: workout-images-001 Retrospective
Feb 7, 2026 — First production cycle for 10X Coder agent
✅ WHAT WORKED
Contract System: Clear acceptance criteria with Promise/Stretch separation. Explicit "ACCEPT/MODIFY/DECLINE" gate before work starts. Defined success metrics upfront (41+ images = 50% coverage).
Two-Phase Protocol: Phase 0 (acceptance) prevented rushing into work. Gave opportunity to catch scope issues before burning cycles. Coordinator approval ("BEGIN WORK") created accountability checkpoint.
Technical Context: Contract included specific file paths, API details, naming conventions. Wger API integration delivered 24 valid images. The Promise deliverable (update exercises.json, update UI) was completed.
❌ WHAT FAILED
Frame Extraction Approach: Card photo cropping was fundamentally broken. ffmpeg grabbed random frames (carpet, wrong exercises). Only 1 of 14 extractions was correct (7% accuracy). Root cause: No validation step before marking as "done".
No Intermediate Checkpoints: Lost visibility during long-running work. Couldn't catch the frame extraction issue until final QA. No "show me 3 sample extractions before proceeding".
Session Label Confusion: Used both 10x-images-001 and 10x-images-002 without clear handoff. Hard to trace what happened in which session post-facto.
Stretch Became Mixed with Promise: Card cropping was listed as "Stretch" but became attempted as Promise. Should have stopped after Wger images + declared Stretch incomplete.
📈 METRICS
| Metric | Target | Actual | Status |
|---|---|---|---|
| Wger API coverage | 50% (41) | 29% (24) | ⚠️ Below target |
| Card extraction accuracy | N/A (Stretch) | 7% (1/14) | ❌ Failed |
| Total coverage | — | 46% (38/82) | ⚠️ Partial |
| Deployment | ✅ | ✅ | ✅ Complete |
🔧 PROCESS IMPROVEMENTS
| Issue | Fix |
|---|---|
| No intermediate validation | Add checkpoint gates: "After 5 images, pause for QA" |
| Session tracking confusion | Single session label per cycle, numbered phases (001-phase-1, 001-phase-2) |
| Stretch/Promise bleed | Explicit "STRETCH START" gate requiring coordinator approval |
| Frame extraction failure | Vision-based validation: "Show sample crops before batch" |
| Lost visibility | Mandatory memory/checkpoint.md updates every 30min |
💡 Verdict: The contract system works — it forced clarity upfront and created accountability. The failure was in execution monitoring and validation gates. The Stretch item (card cropping) should never have been attempted without a proven approach.
Recommendation: For the next cycle, add explicit QA checkpoints at 25%, 50%, 75% completion. Stretch items require separate "STRETCH APPROVED" confirmation.